Uma ferramenta muito útil do Python quando se quer desenvolver sites com Angular é o pacote nodeenv. O nodeenv basicamente faz pelo JavaScript o que o virtualenv faz pelo Python: permitir instalar localmente outras versões do node.js no seu usuário local ou diretório do projeto e apontar a configuração (PATH) para o novo caminho com um simples comando do terminal. Isso é útil quando você está desenvolvendo aplicações web que exigem versões diferentes do Angular. E você nem precisa ter o node pré-instalado na máquina, bastando para isso o Python com nodeenv.
Uma ideia para forçar o seu projeto a sempre ter a versão correta do node.js para executá-lo é criar um ambiente virtual no próprio repositório do projeto e NÃO instalar o node.js para o sistema inteiro. Aí você não corre o risco de executar o ambiente com a versão errada do interpretador e pacotes incompatíveis. Você pode ter um novo node.js funcionando completamente em questão de segundos. Felizmente o nodeenv está disponível diretamente no Fedora e Debian, mas pode ser instalado também com o comando:
[pedro@fedora ~]$ sudo pip install nodeenv
Você pode inclusive instalá-lo no mesmo projeto que o virtualenv se não quiser instalar nodeenv no sistema inteiro, basta ter um diretório separado para o Python e outro para o node.js. O comando a seguir instala uma nova cópia do interpretador no diretório env dentro do diretório do projeto:
E como podemos ver, o prompt também se altera para indicar que estamos num ambiente virtual diferente, assim como o virtualenv faz com o Python. E agora está pronto para uso, inclusive para instalar os pacotes necessários apenas ao projeto em questão:
[pedro@fedora MeuProjeto]$ npm install
Depois de terminado você pode simplesmente fechar o terminar ou desativar o ambiente virtual digitando:
Olhando a documentação técnica do MSX2, parece que a resolução gráfica SCREEN4 (ou GRAPHICS3 no manual técnico do Yamaha V9938) é precariamente suportada pelos desenvolvedores do hardware e do software em geral. Pelo lado de hardware, a resolução não tem suporte a diversas funções de aceleração gráfica do V9938, como acesso ao blitter. Pelo lado do software, ela tem por padrão uma organização da memória mal planejada (com overlap de diversas tabelas distintas do VDP), escolhas estranhas (resolução de 192 pixels na vertical quando o sistema consegue oferecer 212) e falta de suporte a páginas de VRAM adicionais pelo BIOS.
Diante de tanta bizarrice, a velha limitação técnica do attribute clash herdado da SCREEN2 do MSX, que obriga grupos de 1×8 pontos a ter apenas duas cores, parece ser a menor delas. Até porque, por conta dessa economia de memória, ela é rápida o suficiente para realizar scroll horizontal por força bruta se necessário. Não é a toa que um dos mais celebrados jogos do MSX2, o Space Manbow, usa esta resolução.
O objetivo da semana era portar a biblioteca ubox MSX lib para usar a SCREEN4. Qual seria a dificuldade afinal? Sendo a SCREEN4 tão parecida com a SCREEN2, não é mesmo? Seria o melhor dos dois mundos: a velocidade da SCREEN2 com as funções de scroll e sprites do MSX2. Easy peasy lemon squeezy! Só que eu ainda tinha minhas dúvidas por conta da falta de suporte às diversas coisas que o V9938 tem a oferecer, mas o Parn confirmou que o scroll vertical não era uma delas. Verificando rapidamente com um pouco de código em BASIC, fui tratar de aprender mais a fundo como funciona esta resolução.
Para um apanhado geral sobre o funcionamento dos modos de vídeo do MSX, eu aconselho este ótimo artigo do Giovanni, pois aqui eu vou me limitar mais aos poucos avanços que o V9938 oferece à SCREEN4 bem como suas peculiaridades. Talvez mais tarde eu fale sobre a SCREEN2, pois eu andei brincando de suportar modos gráficos em Forth anteriormente e ainda pretendo falar mais sobre isso no futuro. 🤓
Para começar, a tela gráfica SCREEN4 parece dispor da mesma organização de memória que a SCREEN2: 3 tabelas de padrões (os desenho dos caracteres), 3 tabelas de nomes (os índice dos caracteres das tabelas anteriores), 3 tabelas de cores dos padrões (as cores de frente e fundo dos caracteres, por linha), a tabela de padrões de sprites (os desenho dos sprites) e a tabela de atributos de sprites (que reúne índice do sprite e suas coordenadas).
figura 1: organização da memória da SCREEN2.
Mas não é bem assim devido a uma grande novidade: o V9938 traz o registrador #23 que controla o scroll vertical da tela e pra isso acontecer é preciso ter… mais tela! O que isso quer dizer é que a tela é apenas uma janelinha que exibe um pedaço de uma área maior. Uma área maior significa mais memória. Antes, as três tabelas de padrões do MSX1 permitiam cobrir a tela inteira com padrões, pois 8 pontos por caractere × 8 colunas de caracteres × 3 tabelas de padrões = 192 pontos. Mas com a VRAM extra e o registrador de scroll vertical, o MSX2 reserva 256 pontos verticais para a tela inteira, então a resolução vertical máxima de 192 ou 212 é apenas uma janela que exibe uma parte desses 256 pontos verticais, deixando ou 64 ou 44 pontos de fora.
Pra preencher o espaço extra, o V9938 traz as seguintes novidades: uma tabela adicional de padrões, uma tabela adicional de nomes e uma tabela adicional de cores. Na SCREEN4, isso significa que são 4tabelasde padrões, 4 de nomes e 4 de cores (8 pontos por caractere × 8 colunas de caracteres × 4 tabelas de padrões = 256 pontos). Então vamos colocar isso tudo num mapa da memória?
Isso é o que aparece por default quando escolhemos a SCREEN4 e já de cara vemos um problema: considerando que existem mais tabelas para representar a tela e as tabelas precisam ser contínuas, há agora um overlap entre três tabelas. A quarta parte da tabela de padrões preenche todo o espaço que antes era destinado para a tabela de nomes e de atributos de sprites, até encostar na tabela de cores. A tabela de nomes também cresceu e cobriu a tabela de atributos de sprites. Fora isso, a tabela de cores agora cobre a tabela de padrões de sprites. São quatro tabelas se sobrepondo porque essas áreas de memória foram configuradas para serem compatíveis com a SCREEN2 e sua memória reduzida de 16k, o que quer dizer que tentar exibir o conteúdo do 1/4 restante da tela resultará em um monte de lixo inutilizável. Pior que isso, tentar escrever nessa região acarretará no aparecimento de caracteres aleatórios por toda tela, pois a tabela de nomes inteira esta inserida na mesma região. Além de sprites aleatórios aparecendo por todo lugar, ótimo para a criação de glitch art. 😅
Felizmente esse problema é fácil de resolver, pois o V9938 dispõe de registradores especiais que permitem mudar a região da memória que essas tabelas usam. Com 128k de RAM dá pra espalhar bem essas tabelas e poderíamos até criar várias páginas distintas para a SCREEN4 usando apenas o registrador R#2. Vamos começar com algo simples em BASIC mesmo:
10 SCREEN 4:COLOR 15,1,4
20 REM Ajuste das tabelas de VRAM
21 VDP(2)=&H10
22 VDP(3)=&HFF
23 VDP(11)=&H0
24 VDP(4)=&H3
25 VDP(5)=&H8F
26 VDP(12)=&H0
27 VDP(6)=&H9
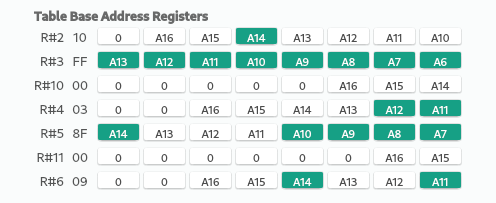
Os comandos VDP() em modo escrita nos permite alterar valores dos registradores do VDP. Nenhum efeito muito visível ainda, mas isso é apenas para ajeitar as tabelas, removendo os overlaps. Uma ótima forma de futucar com esses valores manualmente é instalar o depurador do OpenMSX e selecionar a opção VDP registers view enquanto estiver na resolução correta e clicar nos bits da tabela Base Address Registers. A tabela de decodificação exibe a alteração na mesma hora:
Mas antes de desenhar, devemos colocar nas áreas de memória VRAM os valores esperados para o programa funcionar como se espera. Infelizmente as funções do BASIC não operam nessa região, então precisaremos invocar as alterações via VPOKE nós mesmos.
30 REM Limpa regiao de memoria escondida
31 FOR I%=&H1800 TO &H1FFF: VPOKE I%,0:NEXT
32 FOR I%=&H3800 TO &H3FFF:VPOKE I%,1:NEXT
33 FOR I%=0 TO 255:VPOKE &H4300+I%,I%:NEXT
34 FOR I%=&H4400 TO &H4FFF: VPOKE I%,0:NEXT
Para deixar a tela em branco (ou melhor, preto), preenchemos a quarta parte da tabela de padrões com o byte00 (linha 31). Depois preenchemos a tabela de cor com o byte em 01, que representa a cor de frente transparente e fundo preto, para ficar igual ao restante da tela (linha 32). Então preenchemos a tabela de nomes com bytes de 0 até 255 (linha 33), porque é a tabela de nomes que nos permite desenhar na tela inteira, apenas alterando a tabela de padrões nos lugares corretos. E, por fim, preenchemos as tabelas de sprites com zero para ocultá-la totalmente (linha 34). Agora, por falta de um suporte melhor do BASIC para desenhar na nova região de memória, vamos encher a tela de texto:
50 OPEN"GRP:"FOR OUTPUT AS #1
51 FOR K%=0 TO 191 STEP 64
52 FOR J%=0 TO 63 STEP 8
53 FOR I%=0 TO 31
54 PRESET(I%*8,K%+J%)
55 IF J%=0 THEN GOSUB 60 ELSE GOSUB 61
56 NEXT:NEXT:NEXT
57 FOR I%=0 TO 2047:A=VPEEK(I%):VPOKE &H1800+I%,A:NEXT
58 FOR I%=0 TO 2047:A=VPEEK(&H2000+I%):VPOKE &H3800+I%,A:NEXT
59 FOR I=0 TO 255 STEP .125: VDP(24)=I:NEXT:GOTO 59
60 PRINT #1,CHR$(1)+CHR$(65+I%): RETURN
61 PRINT #1,CHR$(J%*4+I%): RETURN
Estou usando PRESET para marcar a posição em que o texto será escrito (linha 54). Observe que o BASIC não nos permite escrever no quarto final da tela pelo suporte de software incompleto a este modo, então escolhi copiar a tabela de padrões (linha 57) e também a tabela de cores (linha 58) do primeiro quarto da tela para o quarto quarto. A linha 59 serve apenas para mostrar o scroll em funcionamento.
Observe que o registrador de scroll vertical também funciona na SCREEN2, então ela também ficaria com 4 tabelas de padrões e de nomes quando usada no MSX2, mas como o BIOS na SCREEN2 executa em modo de compatibilidade TMS9918, você precisará usar as funções novas do BIOS do MSX2 para manipular endereços acima de 0x3FFF (16k).
No modo SCREEN4, o V9938 dispõe ainda de uma paleta de cores, que permite escolher num espaço de 9 bits (ou 512 cores), 16 delas para pintar a tela. Só que não é bem uma tabela mapeada em VRAM como nos outros casos, pois só tem a finalidade de ser usado em um comando do BIOS que importa cores de imagens lidas do disco em um formato padrão, além de ser em uma área fixa na memória que você poder sobrescrever sem nenhum tipo de efeito colateral.
Coloquei um link para um código de exemplo para manipular o scroll vertical na SCREEN4aqui. O resultado está nesta animação:
Scroll vertical na SCREEN4.
OK, pessoal. Por enquanto é isso. Na próxima parte deste artigo, falarei sobre como implementar páginas de VRAM.
Existem diversas opções fáceis de sincronização de compartilhamentos no GNU/Linux (como o InSync ou ODrive), mas estas costumam ser pagos, pois são produtos de terceiros já que o Dropbox, OneDrive ou o Google Drive não oferecem soluções nativas no sistema, infelizmente. Mas se você estiver disposto e for paciente para trabalhar a linha de comando, é possível configurar uma solução totalmente grátis usando o software livre rclone, o canivete suíço dos aplicativos de compartilhamento em nuvem (palavras do próprio). Outra vantagem do rclone é que ele suporta drive compartilhado (antes conhecido como Team Share), recurso que falta à maioria das opções, até mesmo as pagas.
Primeiro instale o aplicativo rclone que já deve estar disponível no repositório da sua distro. Para derivados do Red Hat, digite no terminal:
$ sudo dnf install rclone
Ou para derivados do Debian:
$ sudo apt install rclone
E siga os passos de instalação que aparecerem. Depois de terminada esta etapa, existem duas palavras-secretas de configuração que é aconselhável você criar para que o rclone tenha acesso a sua conta. Caso contrário ele usará um acesso compartilhado padrão entre diversos usuários e o limite de operações por segundo é compartilhado também entre todos os usuários que optaram por usar o mesmo acesso padrão, o que pode limitar o número de operações por segundo do rclone e deixá-lo lento. As palavras criadas são sequências longas de letras e números separados por hífen, então é melhor copiar e colar exatamente o que aparece no seu browser. Para criar tais palavras-secretas, acesse o Google Cloud Platform.
No lado esquerdo superior clique na caixinha Select a project. Uma janela popup abrirá com um botão no lado direito superior escrito NEW PROJECT.
Uma nova tela se abrirá perguntando o nome do projeto e a organização responsável.
Digite rclone no campo Project name para ficar mais fácil identificar que se trata do aplicativo rclone acessando o seu compartilhamento. E em seguida aperte no botão CREATE. Agora o browser deve voltar a tela inicial. Selecione agora a opção no painel lateral API & Services > Credentials. Na tela que aparecerá, clique no dropdown+ CREATE CREDENTIALS no topo da tela e selecione o item OAuth client ID.
Uma nova tela aparecerá com uma combo box chamada Application type. Selecione o item Desktop app. Uma caixa de texto chamada Name aparecerá. Coloque um nome que identifique que se trata do rclone (um simples “rclone” já vai servir) e em seguida clique no botão CREATE. Um popup contendo as informações que você precisa aparecerá. Salve os dados ali em um editor de texto, pois eles serão usados depois para configurar o rclone em linha de comando. Faça download também do arquivo JSON.
Os seus dados serão obviamente diferentes. 😁
Em seguida selecione APIs and Services > Dashboard no menu lateral. Na tela nova que aparecerá, selecione o botão + ENABLE APIS AND SERVICES. Na tela de API Library, encontre no Google Workspaces a caixa onde está escrito Google Drive API e clique nela. Uma nova tela se abrirá, onde você pode ativar (botão ENABLE) esta API.
Após ativada a API do Google Drive, você deve voltar no item da barra lateral APIs & Services > OAuth consent screen e incluir o seu e-mail na lista de usuários de teste (o botão + ADD USERS) em Test users, caso contrário o Google não libera o acesso ao aplicativo. O e-mail é o mesmo do compartilhamento.
Terminada esta parte, você deve digitar o comando rclone config no console. Ele serve como um wizard de configuração, mas se ficar ainda um tanto confuso, continue lendo. Ao entrar no modo config, o rclone apresenta as seguintes opções:
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q>
Crie um novo remote (que é o nome como o rclone chama o seu compartilhamento remoto) selecionando a opção n de New remote. Em seguida ele pede o nome do compartilhamento. O melhor é selecionar um nome que faça sentido pra você. Digamos que você quer sincronizar a partir da pasta Documents no Google Drive, então você poderia chamá-lo disso. A próxima pergunta é o tipo de compartilhamento e aqui você seleciona Google Drive se for o caso, mas existem muitas opções possíveis… e fora do escopo deste artigo. 😅
Em seguida, ele perguntará o client_id, que é aquela palavra-secreta que você gerou no Google Console. Copie e cole neste espaço. Faça o mesmo para a outra palavra-secreta anotada: client_secret. Em seguida, em scope, você define o tipo de acesso ao compartilhamento. O mais prático é a opção 1 que dá acesso completo de leitura e escrita. Mas podem haver outras opções interessantes ali também. Veja o que atende melhor o seu caso.
root_folder_id é um código que representa a pasta que você quer ter acesso. Deste modo, é possível criar um ponto de acesso a um diretório específico em qualquer lugar do compartilhamento, como por exemplo se você tiver no seu compartilhamento o diretório Backup/Laptop/Documents, você pode associar isso com a pasta Docs localmente e acessa todos os arquivos e diretórios lá dentro. Você consegue descobrir o código do diretório que quer compartilhar entrando no Google Drive e indo até o diretório em questão e copiando o nome que aparece na caixa de navegação depois do https://drive.google.com/drive/folders/, por exemplo:
O código 1oGzNph32h4MS0EFghWNnealE09Vpruj representa o diretório atual My_New_Folder.
A pergunta sobre o campo service_account_file poderá ser deixado em branco. Depois, o rclone perguntará se é necessário editar a configuração avançada. Você pode dizer que não.
Coragem, falta pouco agora!
Pra terminar, o rclone pergunta se pode usar auto config. Isso fará com que o aplicativo em terminal abra o browser pra acessar a sua conta do Gmail. A tela seguinte aparecerá porque o aplicativo está em modo de Teste, mas não tenha medo: é normal e seguro.
Selecione continue para aparecer a próxima tela:
Aqui você deve clicar em Continue novamente e o rclone cria um servidor web temporário para exibir a seguinte mensagem:
Essa última tela pede para você voltar para o terminal do rclone, que deve estar deste jeito:
Log in and authorize rclone for access
Waiting for code...
Got code
Configure this as a Shared Drive (Team Drive)?
y) Yes
n) No (default)
y/n>
Aqui você pode selecionar n se o ponto de acesso não for um drive compartilhado. Depois o rclone apresenta um resumo das configurações e a última pergunta é se está tudo OK. Ou você pode editar tudo de novo até arrumar a configuração. Quando você tiver terminado, ao voltar para o terminal digite sem os <>:
$ rclone mount <nome do remote>: ~/<meu diretório local> &
E você pode colocar essa linha no seu .bash_profile pra executar o rclone a cada login. Observe a presença do &, que coloca o comando em segundo plano e executá-lo como se fosse um daemon, senão ele travaria o terminal ou script eternamente. Foi trabalhoso, né? Mas pelo menos você não precisará fazer isso muitas vezes. 😁
Dica de uso: se você usa aplicativos pra criar notas localmente, como o RedNotebook, você pode colocar as notas que cria em uma pasta sincronizada do Google Drive e compartilhar essas notas entre todos os computadores e smartphones que possui.
Aviso: este artigo apenas descreve uma ideia ou dica de como resolver um problema. Não é minha responsabilidade se você testar a ideia aqui e seu computador subitamente congelar e pegar fogo. Prudência do leitor é aconselhável. Grato pela compreensão. 😉
Usando mais de uma distro de GNU/Linux em um mesmo computador, é comum nos vermos com o problema de lembrar em qual delas está um arquivo de que precisamos. Além de fazer backup do que vale a pena guardar (sempre recomendado), a triagem desses arquivos espalhados por diversos $HOMEs pode consumir muito do nosso tempo e paciência. O ideal, a curto prazo, seria manter sincronizado todo o conteúdo a que temos acesso, ou seja, tudo que está nas pastas Vídeos, Downloads, Imagens e Documentos automaticamente sincronizado entre todas as $HOMEs de todas as instalações de distros na mesma máquina. Desta forma a tarefa de backup tende a ser bem mais simples.
Para resolver esse problema, vamos usar um recurso muito popular quando trabalhamos com contêineres, mas que geralmente funciona debaixo dos panos: o unionfs. Apesar do nome, o union filesystem não é um sistema de arquivos propriamente dito, mas um serviço que se comporta como um, porque ao invés de ler e interpretar o conteúdo de uma partição (os formatos NTFS ou ext4 como exemplos), ele permite fundir dois ou mais diretórios em um único diretório. A beleza disso tudo é que esses diretórios podem estar em diversos sistemas de arquivo diferentes, o unionfs gerencia isso de forma transparente.
Para usar o unionfs como é usado neste artigo, você vai precisar instalar os pacotes do fuse (file system in userspace) e a implementação de unionfs em fuse, que deve ter um pacote com o nome unionfs-fuse ou algo parecido. Talvez exista também na sua distro um pacote chamado fuse-libs do qual fuse depende. Verifique como instalar esses pacotes na sua distribuição favorita. Concluída esta parte, o fuse permitirá que você declare suas configurações no /etc/fstab e as carregue durante o boot.
Voltando ao assunto, considere a forma como o diretório $HOME é organizado. Sabemos que arquivos de configuração criados e usados por aplicativos do usuário geralmente ficam escondidos na sua$HOME. Eles são criados com um ponto inicial (.bashrc, por exemplo) ou ficam agrupados em subdiretórios cujo nome começa com um ponto inicial (.config, por exemplo). Considerando também um bom hábito não popular o diretório $HOME com arquivos avulsos, poluindo ele e o deixando mais lento. Sempre guarde os arquivos em algum subdiretório (mais tarde você verá que esse pequeno detalhe de organização será importante para o tipo de solução que vou propor aqui).
Outra coisa importante sobre o unionfs é que ele define camadas por ordenação. O que isso quer dizer na prática é que, pra definir onde um arquivo novo vai parar quando ele é criado, a ordem de declaração dos diretórios é usada. Digamos que você tenha a seguinte configuração no seu /etc/fstab:
/A=rw:/B=rw /C fuse.unionfs
Ou seja, você vai unir os diretórios A e B, ambos com permissão de escrita, em um diretório C, o diretório que vem antes na definição (A) será o diretório que receberá um arquivo criado. Isto quer dizer que se você criar um arquivo em C (como o diretório C é apenas um ponto de montagem, não armazena nenhum conteúdo e tudo que está lá é virtual), tal arquivo acabará sendo criado em A. Pode-se testar isso criando um arquivo vazio em C com o comando de terminal touch e verificando onde ele está realmente:
[hal9000 /]$ cd C[hal9000 C]$ touch arquivo[hal9000 C]$ ls arquivo
arquivo[hal9000 C]$ cd /A[hal9000 A]$ lsarquivo[hal9000 A]$ cd /B[hal9000 B]$ ls arquivols: cannot access 'arquivo': No such file or directory
Como podemos ver, o arquivo na verdade acabou sendo criado no diretório A. Isso me levou a ideia de como usar o unionfs para fazer a sincronização dos conteúdos distribuídos.
Saindo de nosso exemplo hipotético para algo mais concreto, temos dois tipos de diretório que devemos considerar nessa organização: o diretório contendo os arquivos que queremos compartilhar entre todos as instalações de GNU/Linux e o diretório não compartilhado, que pertence apenas àquela instalação específica. Essa distinção se faz necessária porque existem arquivos que não queremos que estejam compartilhados entre mais de um sistema operacional: arquivos de configuração (sim, aqueles arquivos que começam com um ponto).
Arquivos de configuração são pertinentes apenas para os programas presentes em uma determinada instalação. Se você compartilhá-los e um outro sistema na máquina tiver uma versão diferente do mesmo aplicativo, você pode acabar esbarrando com crashes ou outros erros difíceis de detectar ao tentar executá-los. Ou, em pior caso, pode até perder suas configurações por causa de uma versão mais antiga de um programa que sobrescreveu um arquivo de configuração e ignorou dados que ele não reconheceu, mas que seriam úteis para uma versão mais nova do programa que está em outro sistema operacional na mesma máquina. Então, tenha isso em mente quando for organizar as suas configurações.
Prosseguindo com este exemplo, você pode criar uma partição extra de 1TB e usá-la para os arquivos compartilhados e montá-la em /media/extra; enquanto que o diretório com os arquivos de configuração pode ser bem menor, e ficar em /home/cfg no sistema atual. Você pode agora juntá-los para criar o diretório $HOME do usuário fulano da seguinte forma:
Como /home/cfg é o diretório da primeira camada, isso garante que ele receberá todos os arquivos de configuração criados pelos aplicativos que você executar depois. E o diretório /media/extra é onde estão todos os arquivos que você deseja compartilhar em subdiretórios como Downloads, Imagens, Documentos etc. Se você sempre gravar seus arquivos em algum desses subdiretórios, você já estará automaticamente tornando esses arquivos compartilhados entre todos os outros $HOMEs que você possuir (e aí está o motivo pra você não deixar arquivos jogados na raiz da sua $HOME). Se você quiser criar um diretório novo a partir da base (ou seja, a partir de $HOME) e garantir que ele será compartilhado, você pode criá-lo diretamente em /media/extra e ver ele automaticamente replicado em /home/fulano.
Segundo o manual do unionfs-fuse, temos ainda várias opções úteis para montar o unionfs. A opção cow (copy-on-write) define quando um arquivo é efetivamente criado. Vale a pena manter essa opção ativa por questão de performance. A opção max_files define o número de arquivos abertos simultaneamente. O default é 1024. A opção allow_other permite que outros usuários acessem os arquivos naquele file system, o que é geralmente útil, especialmente se seus usuários em diversos sistemas variam em UID e GID.
Então, apesar das vantagens de organização e economia de espaço, existem alguns cuidados a se considerar:
Se você trabalha com IDEs grandes e pesadas como Eclipse e Android Studio que abrem muitos arquivos simultaneamente, considere usar um parâmetro max_files bem grande, como 16000 (max_files=16000) ou mais quando for criar a uniões de diretórios. Caso contrário você pode acabar tendo comportamentos imprevisíveis com essas ferramentas. O Android Studio, por exemplo, reclamava de não conseguir compilar um projeto montado em uma unidade de rede (?). Experimente brincar com esses valores de max_files até obter um comportamento aceitável e pelamordedeus, use controle de versão. 😉
Mesmo que arquivos de configuração sejam pequenos, lembre-se que o cache do browser e os plugins fica dentro de um subdiretório escondido (por exemplo, .mozilla) na sua $HOME, então lembre-se sempre de reservar alguns gigas para este fim.